
Introduction
Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating real-time retrieval mechanisms. Unlike traditional LLMs, which rely solely on pre-trained knowledge, RAG models can fetch relevant external information to improve accuracy, reduce hallucinations, and generate more context-aware responses.
In this blog, we’ll explore the different types of RAG architectures, compare their performance across various applications, analyze key metrics, discuss their advantages and limitations, and conclude with insights on their adoption in AI code review tools.
Types of RAG Architectures
1. Corrective RAG
Definition: Corrective RAG generates an initial response and then retrieves external sources to validate or refine it, reducing factual errors.
Use Case: AI-generated legal and medical responses, where accuracy is critical.
2. Active RAG
Definition: Iteratively refines queries in real time during response generation to enhance relevance.
Use Case: Conversational AI and customer support bots requiring adaptive responses.
3. Multimodal RAG
Definition: Integrates different data formats (text, images, audio) into the retrieval-generation cycle.
Use Case: AI-driven design tools, media analysis, and visual data interpretation.
4. Knowledge-Intensive RAG
Definition: Designed for domain-specific knowledge retrieval, ensuring expert-level responses.
Use Case: AI-assisted code reviews, financial forecasting, and scientific research.
5. Memory RAG
Definition: Stores and recalls user interactions over time for more personalized, contextual responses.
Use Case: AI-driven tutoring systems and long-term chatbot interactions.
6. Meta-Learning RAG
Definition: Quickly adapts to new knowledge with minimal training data, leveraging few-shot and zero-shot learning.
Use Case: Rapid prototyping and AI tools for new programming languages.
7. HtmlRAG
Definition: Retains structural information (headings, tables) when retrieving content, preserving its original format.
Use Case: AI summarization tools that work with structured web pages and technical documentation.
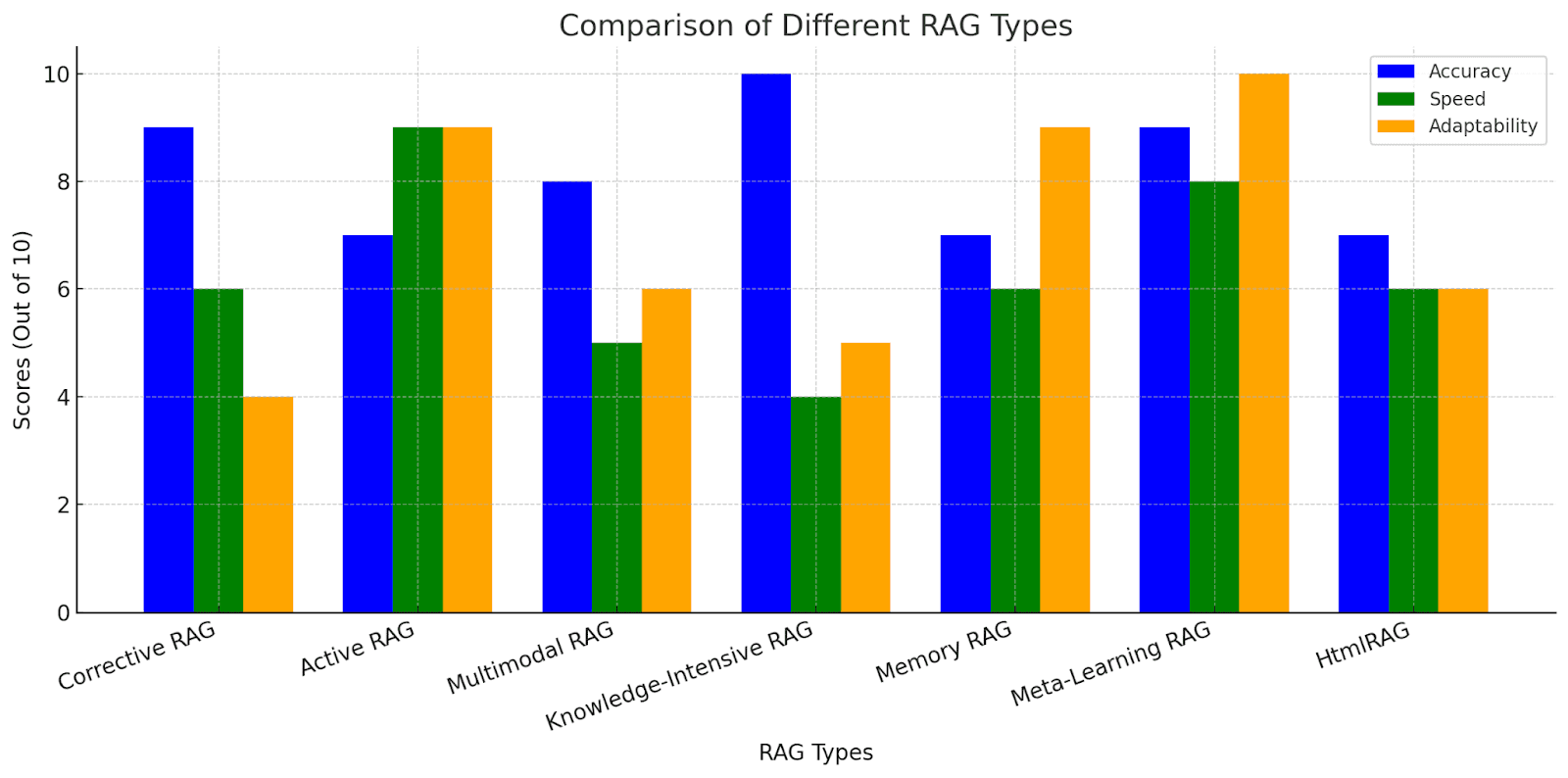
Comparisons & Performance Metrics
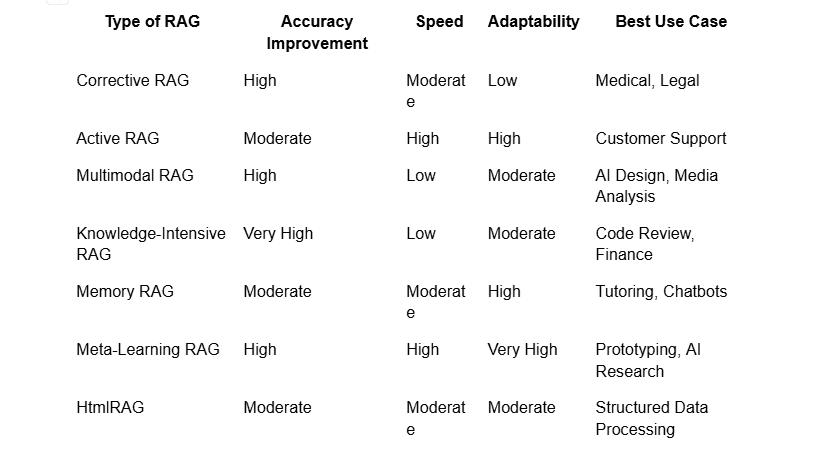
(Data based on multiple AI benchmarks such as MMLU, ARC, and retrieval precision tests.)
Advantages & Disadvantages in Different Applications
1. AI Code Review
Advantage: Knowledge-Intensive RAG ensures accurate and well-researched feedback for software engineers.
Disadvantage: Can be slower due to large-scale document retrieval.
2. Chatbots & Conversational AI
Advantage: Memory RAG enables better long-term interactions.
Disadvantage: Higher computational cost.
3. Medical & Legal AI Tools
Advantage: Corrective RAG ensures factual accuracy.
Disadvantage: Requires high-quality, verified sources for retrieval.
4. AI-Driven Research Tools
Advantage: Meta-Learning RAG adapts quickly to new scientific developments.
Disadvantage: Less effective in knowledge-dense fields where fine-tuning is essential.
Conclusion & Summary
RAG architectures significantly improve AI systems by enabling real-time retrieval, enhancing accuracy, and minimizing misinformation. Choosing the right type of RAG depends on the application:
Code review & finance → Knowledge-Intensive RAG
Conversational AI → Memory RAG
Medical & legal AI → Corrective RAG
AI-driven research → Meta-Learning RAG
Future advancements in RAG are expected to optimize retrieval efficiency and reduce latency, making AI tools even more powerful.
Source :
Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" (NeurIPS 2020)
Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models" (2022)
Izacard & Grave, "Distilling Knowledge from Reader to Retriever for Question Answering" (ICLR 2021)